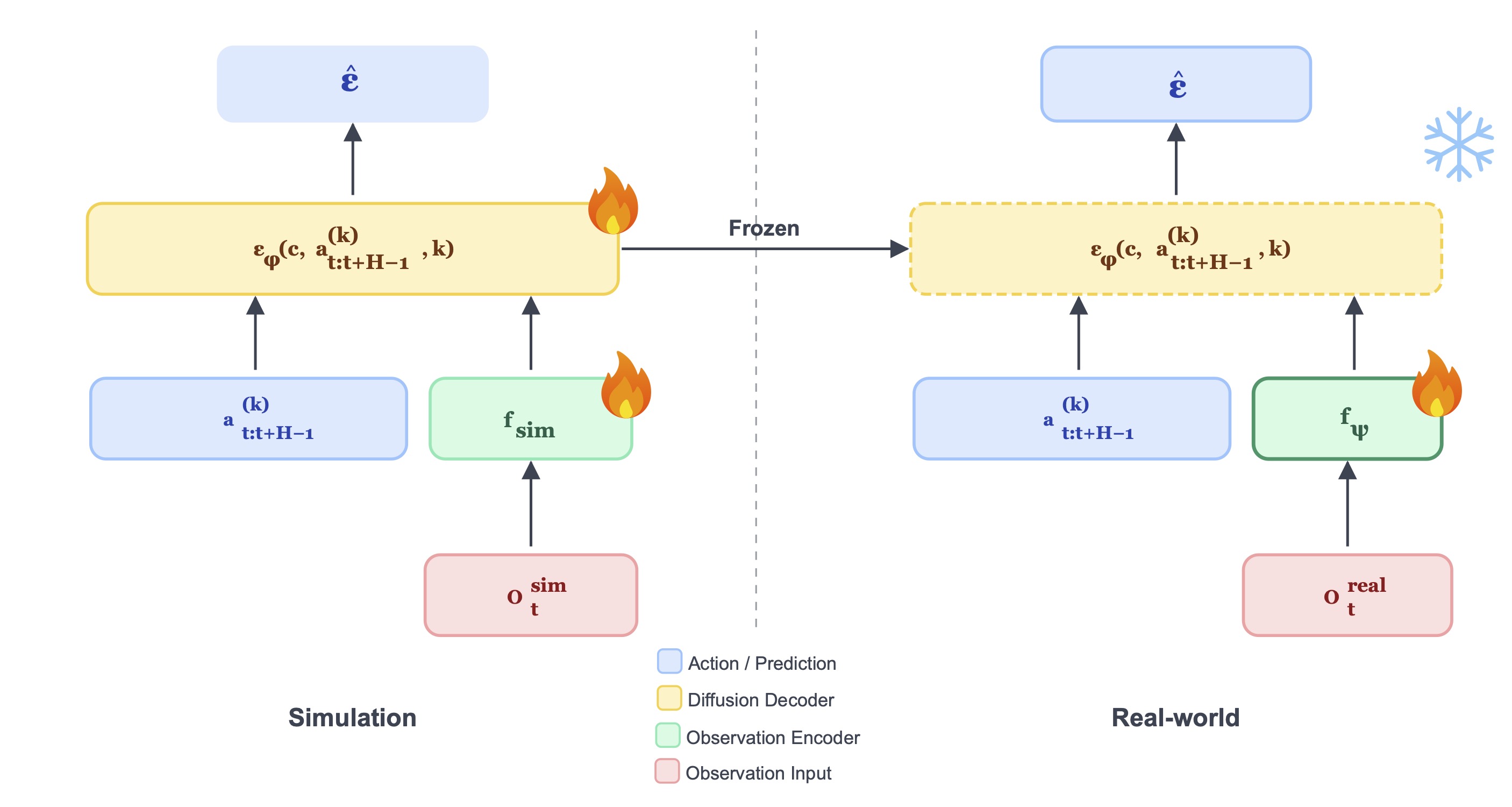
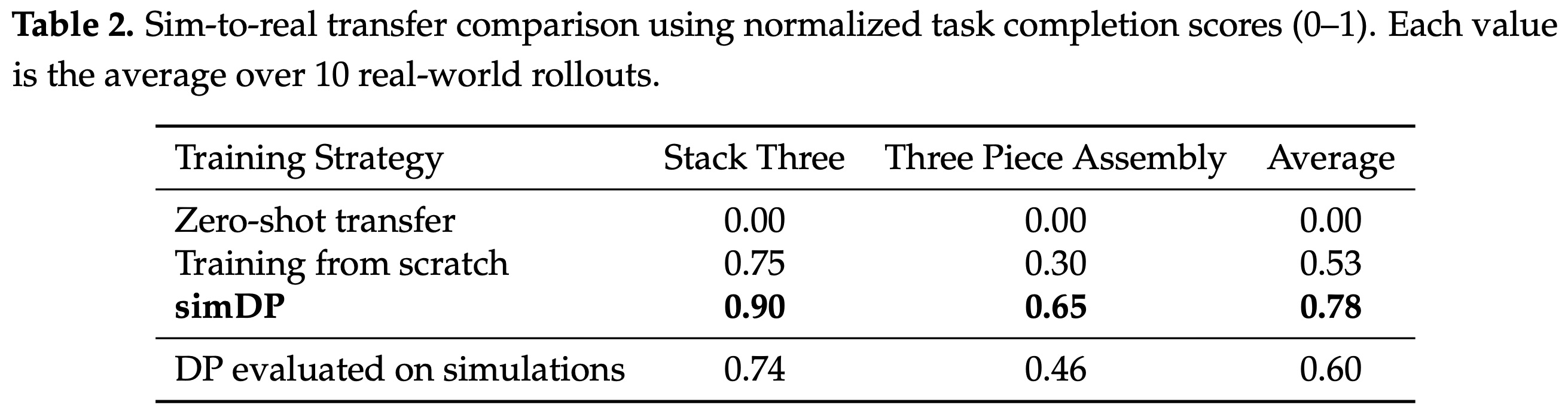
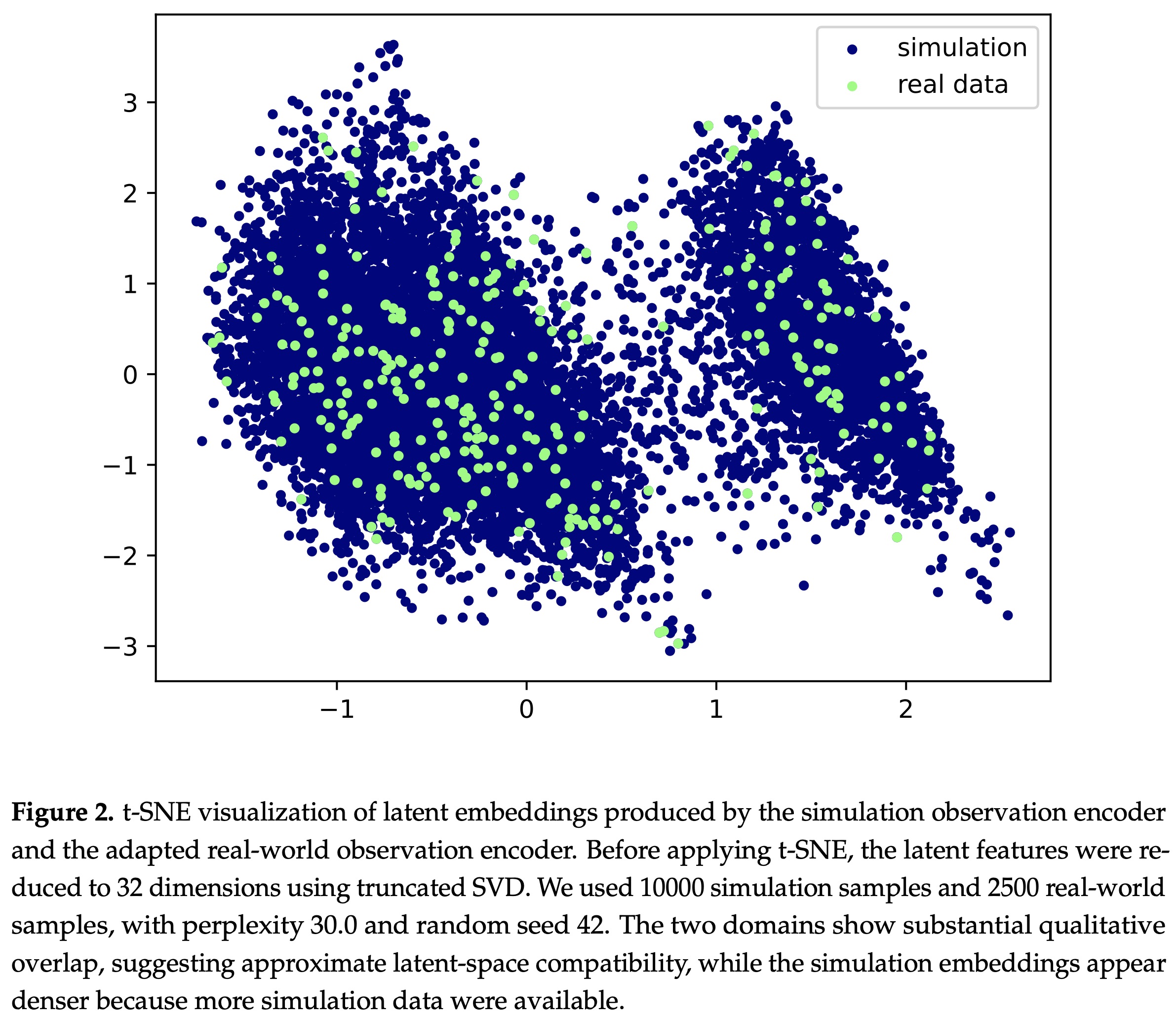
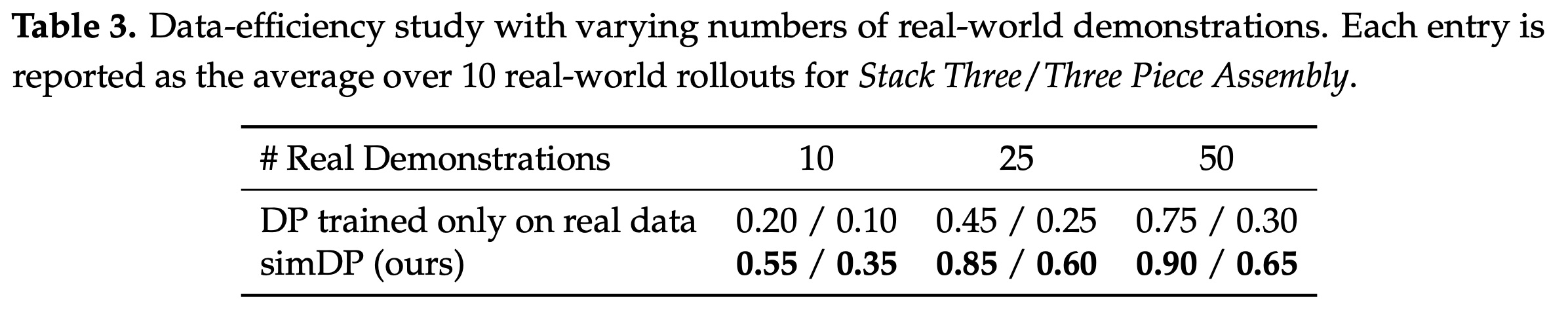
The goal of simDP is to transfer a DP learned in simulation to a
real robot while minimizing the amount of real-world policy
retraining. Our approach is based on two design choices.
-
Instead of robot-sepcific joint commands, represent each action
by the end-effector position, orientation, and gripper state so
that actions are valid in both simulation and real-world
environments: $$a_t = [p_t, r_t, g_t],$$ where \(p_t \in
\mathbb{R}^3\) denotes the Cartesian position of the end
effector, \(r_t \in \mathbb{R}^6\) denotes the end-effector
orientation represented using a continuous 6D rotation
representation, and \(g_t \in \{0,1\}\) denotes the binary
gripper state.
-
Decompose the policy into an observation encoder and an action
decoder, and directly transfer the simulation action decoder and
train a real observation encoder to map visually different
observations to the same latent space.
We chose Diffusion Policy as the baseline visuomotor policy for
sim-to-real transfer. Given the simulation observation encoder
\(f_{\text{sim}}\) and noise prediction network \(\epsilon_\phi\),
the simulation stage training objective is:
$$\mathcal{L}_{\mathrm{sim}} =
\mathbb{E}_{(o_t,a_{t:t+H-1}),\,\epsilon,\,k} \left[ \left\|
\epsilon-\epsilon_{\phi}\!\left(f_{\mathrm{sim}}(o_t),
a_{t:t+H-1}^{(k)}, k\right) \right\|_2^2 \right].$$
In order to directly transfer the simulation action decoder, the
observation encoder must compress the visual information to
discard the aesthetic differences between simulations and
real-world environments. To achieve this, we force the real
observation encoder to produce latent features that are compatible
with the simulation action decoder: $$\mathcal{L}_{\mathrm{real}}
=
\mathbb{E}_{(o_t^{\mathrm{real}},a_{t:t+H-1}^{\mathrm{real}}),\,\epsilon,\,k}
\left[ \left\|
\epsilon-\epsilon_{\phi}^{*}\!\left(f_{\psi}(o_t^{\mathrm{real}}),
a_{t:t+H-1}^{(k),\mathrm{real}}, k\right) \right\|_2^2 \right],$$
where \(\epsilon_\psi^*\) denotes the frozen simulation-trained
action decoder. Here, only the encoder paramters \(\phi\) are
updated.